智能加速算法
1. 传统加速算法
设计了适合硬件实现的省内存的基于单元分割的连通域标记算法。通过硬件实现该算法,实现了世界最快速的基于高速视觉的多目标追踪识别系统,可根据硬件提取的目标特征值进行基于形状、色彩直方图、颜色的快速运动目标的识别及追踪。该系统可以实时运行在2000帧/秒,达到世界最先进水平。
2. AI加速算法
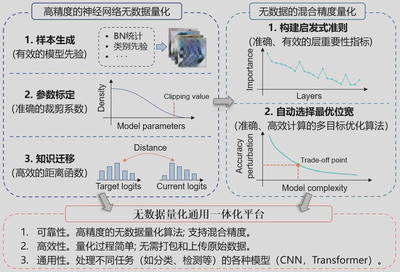
团队研发的高精度深度神经网络无数据量化方法,结合无数据场景的混合精度量化方法,无需任何数据即可达到与数据驱动的方法相当甚至更好的量化性能。并拓展无数据量化到多种视觉任务和模型结构,开发集成无数据量化通用一体化平台。
(1)HTQ:实现混合精度量化的多维最优权衡
混合精度量化,即更敏感的层保持更高的精度,可以实现神经网络的准确性和复杂性之间的权衡。同时,随着硬件社区的发展,越来越多的芯片都开始支持混合精度计算,如Apple A12仿生芯片和NVIDIA Turing GPU芯片,也为混合精度量化提供了广泛的应用前景。然而,混合精度的搜索空间随着层数的增加而呈指数级增长,使得蛮力方法对深度网络是不可行的。为了减少这个指数级的搜索空间,之前的工作使用Pareto边界或整数线性规划来选择每一层的位精度。然而,我们发现这些工作中的约束空间是不够的,导致次优的结果。在实践中,模型复杂度包括空间复杂度和时间复杂度,而这两者是弱相关的,因此仅仅使用一个作为约束条件是不全面的。除此之外,它们还需要手动设置约束条件,这使得它们只是伪自动的。
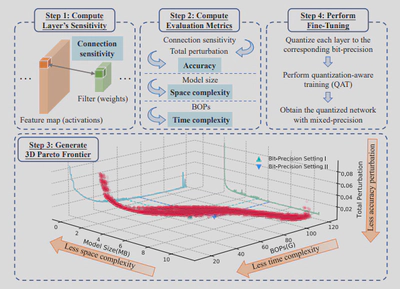
为了解决上述问题,我们提出了High-dimensional Trade-off Quantization(HTQ),如图2,它可以自动确定模型精度、空间复杂度和时间复杂度的高维空间中的最佳位精度,而不需要任何人工干预。具体来说,我们使用基于连接敏感性的显著性标准来表示量化后的精度扰动,其性能类似于Hessian信息,但可以快速计算(速度提高1000×以上)。然后,根据总扰动、模型大小和位操作(BOPs)的三维Pareto边界自动选择位精度,不需要人工约束。此外,HTQ允许对权重和激活进行联合优化,因此可以同时计算两者的位精度。与最先进的方法(如HAWQ-V3)相比,HTQ在图像分类和物体检测任务的各种模型架构上实现了更高的精度和更低的空间/时间复杂性。
(2)DDAQ:双鉴别器无数据量化框架
目前,几乎所有现有的量化方法都严重依赖原始训练数据集进行微调,而由于隐私和安全问题,这些数据集在许多实际场景中无法获取。为了解决这个问题,最近的工作提出了几种无数据量化方法,这些方法基于模型中的先验信息生成样本。然而,它们未能充分地利用先验信息,因此不能完全恢复真实数据的特征,也不能对量化后的模型提供有效的监督,导致性能不佳。
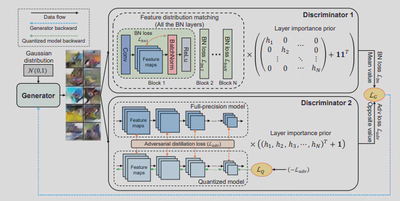
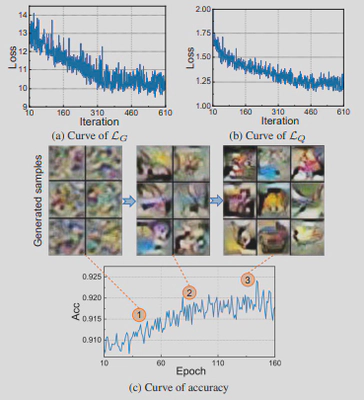
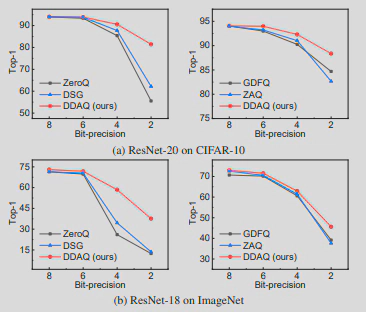
在本文中,我们提出了Dual-Discriminator Adversarial Quantization(DDAQ),这是一种新型的无数据量化框架,具有对抗性学习风格,能够有效地生成样本并学习量化模型,如图3所示。具体来说,我们在两个鉴别器指导下,采用一个生成器来产生有意义的和多样化的样本。两个鉴别器的目的分别是促进BN层分布的匹配和最大化全精度模型和量化模型之间的差异,如图4所示。此外,受混合精度量化的启发,即每层的重要性是不同的,我们在两个鉴别器引入了层的重要性,使我们能够更好地利用模型中的信息。随后,在全精度模型的监督下,用生成的样本训练量化的模型。我们针对不同的视觉任务,包括图像分类和物体检测,在不同的网络结构上对DDAQ进行了评估,实验结果表明DDAQ以良好的通用性超越了所有的基线方法,如图5所示。
(3)CoLeQ:结合对比学习提升无数据量化性能
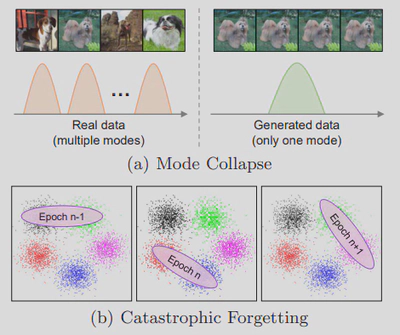
最近,无数据量化被广泛研究,因为它不访问原始数据集,可以解决广泛存在的数据隐私和安全问题。它的主要思想是根据全精度(FP)模型中的先验信息生成假数据,然后在FP模型的监督下用它们训练量化模型。量化性能在很大程度上依赖于生成数据的有效性,然而,现有的方法存在两个严重的问题:模式崩溃和灾难性遗忘,如图6所示,导致了非常显著的精度下降。
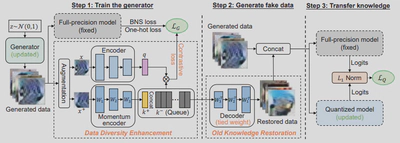
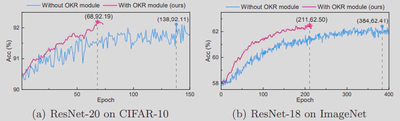
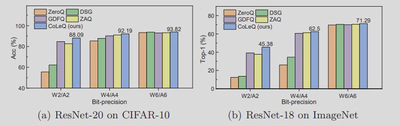
为此,我们提出 Contrastive Learning Quantization(CoLeQ),它通过对比学习实现了数据多样性的增强和旧知识的恢复,以解决上述问题,如图7所示。具体来说,我们在无数据量化中引入了MoCo范式,该范式可以维护一个编码特征的动态动量队列。对比学习的优化目标是通过促进生成的样本与前几批已经生成的样本的分离来提高数据多样性,从而缓解模式崩溃问题。此外,我们设计了一个捆绑权重的解码器,从队列中的编码特征中恢复以前的样本,而不需要额外的参数和训练,因此可以有效地防止灾难性的遗忘问题,如图8所示。为了评估CoLeQ的有效性,我们进行了大量的实验,结果表明与最先进的方法相比,CoLeQ具有一致的优势,如图9所示。
(4)PASQ-ViT:基于Patch相似性的vision transformer无数据量化
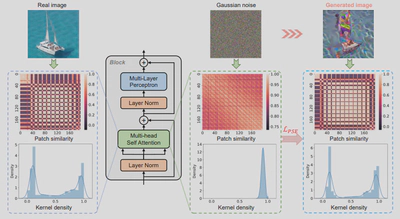
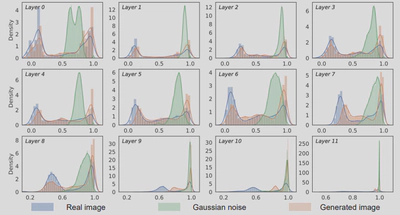
最近, vision transformer在各种计算机视觉任务上获得了巨大的成功;然而,它们的高模型复杂性使其在资源有限的设备上的部署具有挑战性。量化是降低模型复杂性的有效方法,而无数据量化可以解决模型部署过程中的数据隐私和安全问题,因此受到广泛关注。不幸的是,所有现有的方法,如BN正则化,都是为卷积神经网络设计的,不能应用于具有明显不同模型结构的vision transformer。为此,我们提出了Patch Similarity Aware data-free Quantization framework for Vision Transformers (PSAQ-ViT),一个用于vision transformer的基于Patch相似性的无数据量化框架,以便能够根据视觉变换器的独特属性生成“逼真的”样本来校准量化参数,如图10所示。具体来说,我们分析了自我注意模块的属性,并揭示了其在处理高斯噪声和真实图像时的一般差异(补丁相似性),如图11所示。上述见解指导我们设计了一个相对值指标,以优化高斯噪声来接近真实图像,然后利用它来校准量化参数。我们在各种基准上进行了广泛的实验和消融研究,以验证PSAQ-ViT的有效性,它甚至可以优于真实数据驱动的方法。
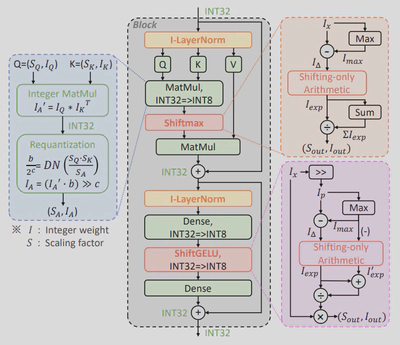
(5)I-ViT:vision transformer的纯整数量化
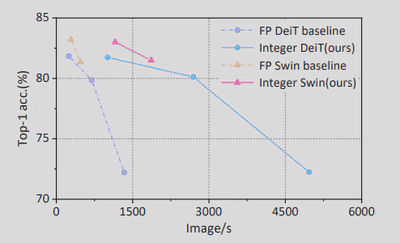
Vision transformers(ViTs)在各种计算机视觉应用中取得了最先进的性能。然而,这些模型有相当大的存储和计算开销,使得它们在边缘设备上的部署和有效推理具有挑战性。量化是降低模型复杂性的一个有效的方法;不幸的是,现有的量化ViTs的工作是模拟量化(又称伪量化),在推理过程中仍然是浮点运算,因此对模型加速的贡献很小,如图12所示。在本文中,我们提出了Integer Vision Transformer (I-ViT),一种针对ViT的纯整数量化方案,使ViT能够用整数运算和位移来执行推理的整个计算图,而没有任何浮点运算,如图13所示。在I-ViT中,线性运算(如MatMul和Dense)遵循纯整数二元算术流水线;非线性运算(如Softmax,GELU和LayerNorm)由提出的轻量级纯整数算术方法近似。特别是,I-ViT应用了新颖的Shiftmax和 ShiftGELU,它们被设计为使用整数位移来逼近相应的浮点运算。我们在各种基准模型上评估了I-ViT,结果表明,纯整数的INT8量化实现了与全精度(FP)基线相当(甚至更高)的精度。此外,我们利用TVM在GPU的整数运算单元上进行实际的硬件部署,与FP模型相比实现了3.72-4.11×的推理加速,如图14所示。