高效深度学习
1. 模型量化
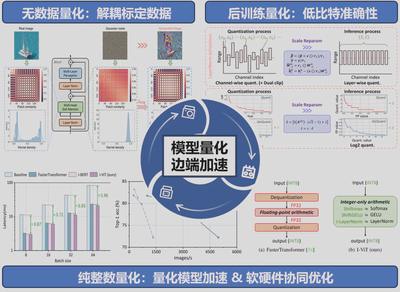
(1)无数据量化方法
- Zhikai Li, Jing Zhang, Qingyi Gu. Privacy-preserving sam quantization for efficient edge intelligence in healthcare. International Journal of Computer Vision, 2026.
- Zhikai Li, Mengjuan Chen, Junrui Xiao, and Qingyi Gu. CoLeQ: Improving data-free quantization via contrastive learning. IEEE Transactions on Multimedia (TMM), 2025.
- Zhikai Li, Mengjuan Chen, Junrui Xiao, and Qingyi Gu. PSAQ-ViT V2: Towards accurate and general data-free quantization for vision transformers. IEEE Transactions on Neural Networks and Learning Systems (TNNLS), 2024.
- Zhikai Li, Liping Ma, Mengjuan Chen, Junrui Xiao, and Qingyi Gu. Patch similarity aware data-free quantization for vision transformers. European conference on computer vision (ECCV), 2022.
无数据量化根据预训练模型中的先验信息合成数据,然后将其用于量化标定,是数据敏感的场景(如军事、医疗领域)中一项必要的技术。提出了一种相对值指标Patch相似度,来引导高斯噪声逐步逼近真实图像的特征分布(ECCV 2022)。此外,引入了对抗学习框架(TNNLS 2024)和对比学习框架(TMM 2025),使图像生成器与量化模型在对抗博弈中持续学习和进化。进一步地,在实际医学图像分割任务上实现了针对性的优化与应用(IJCV 2026)。
(2)量化策略优化
- Zhikai Li, Xianlei Long, Junrui Xiao, and Qingyi Gu. HTQ: Exploring the high-dimensional trade-Off of mixed-precision quantization. Pattern Recognition (PR), 2024.
- Junrui Xiao, Zhikai Li, Lianwei Yang, and Qingyi Gu. Binaryvit: Towards efficient and accurate binary vision transformers. IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2024.
- Zhikai Li, Junrui Xiao, Lianwei Yang, and Qingyi Gu. RepQ-ViT: Scale reparameterization for post-training quantization of vision transformers. International Conference on Computer Vision (ICCV), 2023.
为了提升低比特量化性能,从不同角度和层面对量化策略进行优化。提出了一种基于尺度重参数化的量化-推理解耦范式(ICCV 2023),能够细粒度地识别并去除激活中的异常值。提出了梯度正则和激活偏移(TCSVT 2024),实现超低比特量化,将模型参数推至二值化表达。提出了一种基于高维Pareto最优的混合精度量化方法(PR 2024),实现了模型准确度-内存-计算量的高维最优权衡。
(3)纯整数量化与硬件加速
- Zhikai Li and Qingyi Gu. I-ViT: Integer-only quantization for efficient vision transformer inference. International Conference on Computer Vision (ICCV), 2023.
现有硬件算子不支持模型中非线性组件的整数计算,造成计算图的切割,从而导致不理想的加速效果。提出了一种基于整数算子重构的ViT纯整数量化方法(ICCV 2023),对非线性组件进行计算简化和整数近似,充分受益于快速高效的整数运算单元。此外,基于TVM框架进行编译和计算调度优化,进一步提升了模型计算效率,在GPU图灵张量核心上将推理速度提升了3.72∼4.11倍。
2. 生成模型的压缩与加速
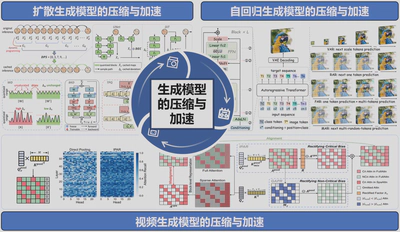
(1)扩散生成模型的压缩与加速
- Xuewen Liu, Zhikai Li, Qingyi Gu. CacheQuant: Comprehensively Accelerated Diffusion Models (CVPR), 2025.
- Xuewen Liu, Zhikai Li, Minhao Jiang, Mengjuan Chen, Jianquan Li, Qingyi Gu. DilateQuant: Accurate and Efficient Diffusion Quantization via Weight Dilation (ACM MM), 2025.
扩散模型的高效部署面临激活值分布复杂、时变性强等挑战。针对量化问题,提出高效量化框架(ACM MM 2025),通过权重扩张技术缩小激活范围、时序并行量化器处理时变特性、块级知识蒸馏降低训练成本,在4-bit量化下实现接近全精度性能,训练效率提升160倍且内存减少3倍。针对加速问题,提出联合优化的免训练加速范式(CVPR 2025),通过动态规划调度和解耦误差校正解决缓存与量化误差耦合累积的问题,首次在时间和结构维度实现全面加速,突破传统方法极限的同时保持生成质量。这两项工作为扩散模型提供了兼具精度与效率的系统性部署方案。
(2)自回归生成模型的压缩与加速
- Xuewen Liu, Zhikai Li, Jing Zhang, Mengjuan Chen, Qingyi Gu. PTQ4ARVG: Post-Training Quantization for AutoRegressive Visual Generation Models (ICLR), 2026.
针对自回归视觉生成模型量化难题,识别出通道异常值、Token动态激活和样本分布不匹配三大挑战,提出首个ARVG专用量化框架(ICLR 2026):通过数学优化推导最优缩放因子抑制异常值、利用ARVG固有特性实现零开销静态Token量化、基于熵度量选择分布匹配样本。该方法在VAR/RAR/PAR/MAR等模型上实现6-bit高精度量化,达到3倍加速和近2倍内存压缩,且无需训练、硬件友好,是首个系统性解决ARVG量化的训练后量化方案。
(3)视频生成模型的压缩与加速
- Xuewen Liu, Zhikai Li, Jing Zhang, Mengjuan Chen, Qingyi Gu. Rectified SpaAttn: Revisiting Attention Sparsity for Efficient Video Generation (arxiv), 2026.
面向视频生成模型模型,针对通用稀疏方法存在的系统性偏差,提出利用池化注意力权重作为隐式完整注意力参考进行偏差修正:通过隔离池化并重分配权重以修正关键token偏差;通过在增益超过误差时补偿非关键token信息,最终实现稀疏与完整注意力的高度对齐。该方法在88.95%高稀疏度下实现3.33×端到端加速且VBench得分保持82.57,结合缓存技术最高达8.97×加速,作为即插即用模块无需训练且开销可忽略,有效突破了高质量视频生成的效率极限。
3. 识别模型的压缩与加速
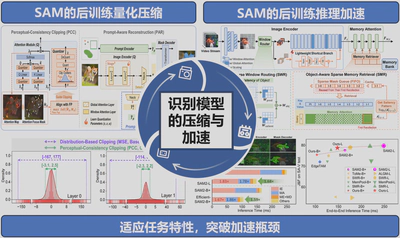
(1)分割万物模型的后训练量化压缩
- Jing Zhang, Zhikai Li, Chengzhi Hu, Xuewen Liu, Qingyi Gu. SAQ-SAM: Semantically-Aligned Quantization for Segment Anything Model(AAAI), 2026.
ViT通用的量化方法在SAM上效果不佳,具体表现为掩码解码器中极端的激活异常值和SAM特有的用户交互模式。提出了为SAM定制的后训练量化方案(AAAI 2026),从语义对齐的角度改善量化模型性能。感知一致性剪裁通过度量注意力焦点重叠度误差来支持语义对齐剪裁;提示感知重建利用掩码解码器中的交叉注意力整合图像与提示的交互,从而促进分布和语义的双重对齐,方法实现了低bit量化的显著性能提升。
(2)分割万物模型的后训练推理加速
- Jing Zhang, Zhikai Li, Xuewen Liu, Qingyi Gu. Efficient-SAM2: Accelerating SAM2 with Object-Aware Visual Encoding and Memory Retrieval (ICLR), 2026.
提出针对SAM2的后训练推理加速方案(ICLR 2026),基于模型的稀疏感知模式与密集计算之间的矛盾,识别图像编码器与记忆注意力中的冗余计算,并分别设计专用加速方案。针对图像编码器,通过将背景窗口路由至轻量级旁路分支进行窗口级的计算调度;针对记忆注意力,基于记忆显著模式的时序一致性进行token级记忆稀疏化。方法仅增加可忽略的额外参数与极低的训练成本,在多个VOS基准测试上展现了卓越的性能-速度权衡。例如,在SAM2.1-L模型上实现1.68倍端到端加速,在SA-V测试集上精度仅下降1%。
4. 高效偏好强化学习
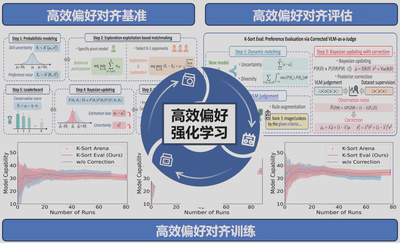
- Zhikai Li, Jiatong Li, Xuewen Liu, Wangbo Zhao, Pan Du, Kaicheng Zhou, Qingyi Gu, Yang You, Zhen Dong, Kurt Keutzer. K-Sort Eval: Efficient Preference Evaluation for Visual Generation via Corrected VLM-as-a-Judge. International Conference on Learning Representations (ICLR), 2026.
- Zhikai Li, Xuewen Liu, Dongrong Fu, Jianquan Li, Qingyi Gu, Kurt Keutzer, and Zhen Dong. K-sort arena: Efficient and reliable benchmarking for generative models via k-wise human preferences. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
提出视觉生成模型竞技场(CVPR 2025, ICLR 2026),基于人类偏好投票来高效评估视觉生成模型的性能。K-Sort Arena采用 K-wise 比较,设计基于探索-利用的匹配算法和概率建模,从而实现更高效和更可靠的模型排名。K-Sort Arena已经历数个月的内测,期间收到来自NUS, CMU, Stanford, Princeton, Peking University等数十家机构的专业人员的技术反馈。目前,K-Sort Arena 已收集几千次高质量投票并有效地构建了全面的模型排行榜,已用于评估几十种最先进的视觉生成模型。